
Your first custom pre-processing tool for memoQ
Let's learn to do useful things in memoQ templates, sometimes by not doing anything at all...

I’ve mentioned before that if you are a loc engineer (or a freelancer doing your own engineering) and want to learn coding, your best choice for a first project is probably solving a case of translation document pre-processing. Sooner or later, all of us encounter a problem where a file to translate has some “flaws” that you want to “fix” to make translation more efficient, or the file that doesn’t play well with your translation tool without some changes. This is when you need to develop a tool to prepare (or pre-process) the file before importing to the translation tool. If you also happen to be a memoQ user, then a pre-processing tool you develop can be plugged right into your template and project, so that the pre-processing is automatically performed as files are imported. The PM can simply drop the file on the project to have memoQ perform the pre-processing. Also, at export, you can have similar automation for any post-processing: memoQ first exports the file, then runs the post-processing tool on it to finalize the file. (The usual goal with post-processing is to undo any changes you made to the file in pre-processing, ensuring that the customer gets the file in the exact same form they sent it to you.) Let’s see how all this works.
The memoQ side
Let’s start in the middle and pretend you have already developed your first pre-processing tool, and you just want to start using it with memoQ. I’m doing it this way because understanding memoQ’s framework for automated pre-processing can be trickier than the actual coding, and when you do the actual coding, you will need to make your tool behave as memoQ expects it to. As is often the case with memoQ, the pre- and post-processing functionality is quite versatile and flexible, but perhaps not immediately self-explanatory. Pre-processing is available for local projects too with the exact same functionality as in an online team project in memoq TMS, so freelancers working without a server are not left out. Both in the local single-user and the team scenario, the pre- and post-processing tools must be added to a memoQ project template. Open a template for editing in memoQ’s Resource console, and click “Automated actions” in the vertical menu on the left. The “Script before import” tab is where you can insert a pre-processing tool, and “Script after export” is for post-processing.
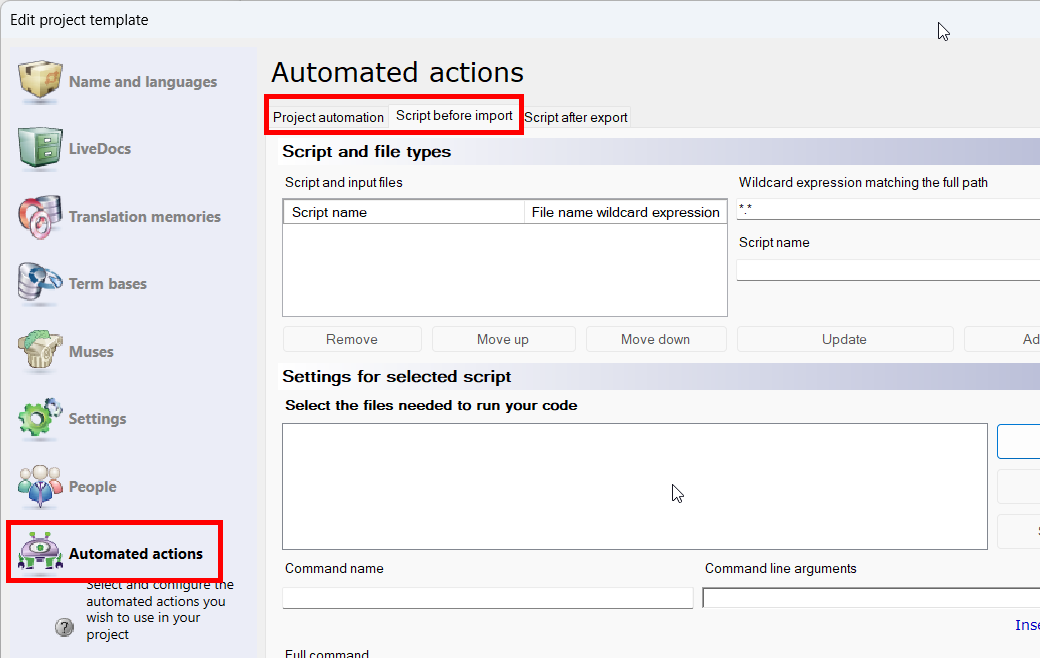
If you click “Add files” and add any executable or script or even batch file that can run in Windows, then something interesting happens:

The command-line arguments and the command are pre-filled with the placeholders {InputFilePath} and {OutputFilePath}. It’s crucial to understand what’s going on to be able to design your first pre-processing tool with the right logic. When memoQ will run your pre-processing tool, it will substitute two paths and file names into these command-line arguments. This means that any tool that you develop for pre- or post-processing in memoQ must take (at least) two command-line arguments: {InputFilePath} is a full file path for one file to be processed, and {OutputFilePath} is the full file path where your tool will place the file after it is modified. The files are always processed one at a time in the automation, even if you are importing many files together. In other words, you must develop a tool or script that you can run manually like this in a command-line window:
your-first-tool.exe "c:\examples\file to translate.txt" "c:\examples\file to translate - prepared.txt"
Let’s see why we need these two command-line arguments, and how exactly they work. When you actually import a file in a project created from the template, memoQ (or memoQ TMS) will do the following steps.
1. memoQ creates two temporary folders, if they don’t exist already. In one of the temp folders, it creates a copy of the file to import. In the other, it creates copies of the files of the pre-processing tool. (The pre-processing tool might consist of more than one file.)
More details for nerds:
You don’t really need to know where these files are, but in case you are interested, here’s an example, assuming an online project:c:\ProgramData\MemoQ Server\Scripting\Data\0008052c-30b2-ef11-b8c4-64497dc129af\k1uxjvm3.txt
c:\ProgramData\MemoQ Server\Scripting\Code\0008052c-30b2-ef11-b8c4-64497dc129af\fbaa26d7-3ee6-4ef3-a1d0-f08509340668\your-tool.exe
(The actual file name of the document to import is renamed by memoQ to some short name consisting of random characters like k1uxjvm3.txt, to avoid issues with a path that could become too long. The other random looking parts are project identifiers used by memoQ.)
2. memoQ runs your tool to perform the pre-processing as configured in the template, using the path of the file to import (from the above temp location) as a command-line argument. When it does this, it substitutes the {InputFilePath} placeholder in the template with the temp path. It also substitutes {OutputFilePath} with a new file name that will be created by the tool. This will be where the modified file goes created by your tool.
More details:
In practice, the actual command line that memoQ executes would be something like this:c:\code-temp-location\your-first-tool.exe "c:\file-temp-location\someRandomFileName.txt" "c:\ file-temp-location \someRandomFileName_out.txt"
Of course, “code-temp-location” is actually something like “c:\ProgramData\MemoQ Server\Scripting\Data\0008052c-30b2-ef11-b8c4-64497dc129af\”. And file-temp-location is something like c:\ProgramData\MemoQ Server\Scripting\Data\0008052c-30b2-ef11-b8c4-64497dc129af\ k1uxjvm3.txt. But, again, you don’t need to worry about this to be able to make pre-processing work.
Unless you do some digging, you won’t even know where these folders are created and what names the temp files get as they are copied into the folder. In the case of an online project, all the pre-processing is performed on the server machine, so these files and folders are there, not on the PM’s computer. When you work in local projects using just a memoQ client and no server, some slightly different locations are used: I haven’t played much with pre-processing without a memoQ TMS / server.
3. After the pre-processing tool is executed, the pre-processed file is imported into the translation project by memoQ.
4. Finally, all the temp files are deleted by memoQ. (Actually, it doesn’t delete the executable or script, because it is very likely that more than one file will be pre-processed and imported using it, so it makes sense to keep it around.)
The general logic of all my pre- and post-processing tools
When I develop new pre- or post-processing tools, I always start from the same simple “boilerplate” code, i.e. I copy and paste a few lines that form the skeleton of all my tools of this type. It makes sense to have such a common skeleton because, in my experience, there are exactly two main ways to use a tool of this type:
The first use case is the one I described above: running the tool in memoQ automation to perform the pre- or post-processing automatically when importing or exporting the file. This works via the two command line arguments
{InputFilePath}and{OutputFilePath}.The second use case is when you want to run the tool manually to process some files. I do this the simplest possible way I could think of: the tool just looks for any input files in the folder where it is run, creates a list of them, performs the modifications required on every file, and then saves the files, overwriting the originals. Since the files often come in a folder structure, the tool goes through every file in every subfolder – which can be very handy and isn’t complex to do at all in C# code nowadays.
Developing the tool
I don’t want to explain programming basics here, so a basic level of understanding C# (or an ability to figure it out) is assumed. (The below code uses the “top level statements” feature for simplicity and brevity: this way, C# becomes similar to scripting languages like Python where you can just start with an empty file, write your first statement, compile and it will work. A program can even be a single line, like Console.WriteLine(“Hello World”);. Lines starting with // in my code are comments: they may help explain the code, but they are ignored when the code is compiled or run, so they don’t affect how the program works.
First, let’s just develop a tool that performs no changes at all: the output file will just be a copy of the input file. In fact, such a tool can already be useful in memoQ: I’ll explain that towards the end of this article.
Substack doesn’t support syntax highlighting for source code, so here’s a link to the code on github, and a screenshot:

This code simply takes the input file creates an output file that is just an unchanged copy. I’ve just counted, and it is just around ten lines without the comments, and I could compress it to fewer lines if I wanted to, but I prefer my code to easily readable. I mention all this just to illustrate that modern C# code doesn’t have to be verbose and intimidating for simple things like this.
If you don’t prefer to read the code and its comments, here’s an explanation. Remember, the tool needs to be applicable both in memoQ automation and in the manual use case of converting many files in a folder. To achieve this, its humble trick is that it checks if there were any command-line arguments. If there are none, it goes on to process every applicable file it finds in the same folder where it is run. If there are at least two command-line arguments, it uses the first one as the path and file name of the file to modify, and the second argument as the path and file name where it must save the modified file. (If you don’t specify valid paths and file names, or if the input file doesn’t exist, the tool will fail with an error.)
Now that we’ve managed to make a tool that does nothing (and while doing nothing still manages to do something which I still want to explain later!), let’s imagine a simple pre-processing scenario that could even occur in real life: a source file written using a flaky keyboard that places a random number of space characters when the author hits the space key between words. The task of our first “real” tool is to replace all sequences of space characters with a single space. We are going to clean up the spaces by changing the heart of our program, the code lines in the foreach loop that makes the actual changes in the file. We’ll read the file into a string and keep replacing double spaces in the string with single spaces until we can’t find any more double spaces. One round of replacing each double space with a single one is not enough, because there might be sequences or three or more spaces, which could be handled of course using regular expressions or similar, but I also wanted to make the program logic very simple. Here’s a screenshot, and a link to github.

Performance
Whenever there is a performance issue in a software product that is well established and is getting complex, some people will shout “bloat” and explain that said software will never ever perform well anymore because it has become too big and complex. However, if you start coding and tackle your first real-life performance challenges, you will quickly learn that size and complexity have little to do with performance: it’s extremely “easy” to develop code that performs way worse than it should, even with a minimal piece of code as the above. (Also, large and complex software can remain performant, if the developers are capable and take care.) So, what is wrong with our code in terms of performance? We’ve barely touched the keyboard, so our code is definitely not “bloated”. It will actually perform very well if the files to process are tiny. However, if the file is huge, it is no longer a great idea to read the whole file into a string. It’s also not optimal to replace text in your (potentially) huge string several times, each time creating a copy of the whole string. With text files, one possible trivial way to address such a problem is to process the file line by line. We can simply deal with one line at a time, get rid of the double spaces, and write it back out. We no longer hold our whole file (which could be potentially enormous) in memory, and we are no longer inefficiently checking for and removing double spaces in an extremely long string.
I’ve created a new version of my “double space eliminator” code, with line-by-line processing. See it on github here. I’ve run some very basic performance tests with an enormous text file: the line-by-line version got rid of spaces in 7 seconds, while the original “whole file as one huge string” version took 12 seconds. Honestly, I thought the difference would be much more dramatic… But if you look closer at the resource usage of the two versions, you can see some very big difference, not in the amount of work the CPU has to do, but in memory usage: the line-by-line version used less than 20 megabytes of memory (which is negligible nowadays and way less than the size of the text file), while the “whole file” version used several gigabytes. Now, wasting memory is “fine” if you are lucky to have lots of free memory in your computer like I do, however, if your computer gets close to running out of physical memory completely, then everything will slow to a crawl. Your PC will start using its storage (the hard drive or SSD) to temporarily store the data it cannot fit into its memory, and storage is magnitudes slower than memory.
The logic of the line-by-line version
In our first naïve solution to the double space problem, we just had a single code line to read a file to a string, and another single line to write the string back to a file after we have “fixed” the double spaces. When you read and write text files line by line in C#, things become a little more complicated. This is the main foreach loop of the line-by-line solution:

First, I needed to use a temporary file. Remember, one of our use cases is processing several or many files at once, overwriting them after changing them. I don’t know if it’s possible to read a file line by line and modify each line before going to the next: maybe it’s doable, but I thought it might be too complex. Instead, the output file is first created in a temporary location, and when we have written its last line, we move it to the final location.
Using the File.ReadLines method is maybe the most important trick here. We have a foreach loop that goes over each line of the source file, but File.ReadLines doesn’t have to finish reading every line to start processing them, and doesn’t have to keep all the lines in memory. Instead, it only reads each line right when they are required, and forgets the line when it is already written out. This makes it possible to run our tool with memory usage that is just a fraction of the source file’s size.
As I’ve said before, I don’t think I’m very good at teaching general C# coding. But to fully understand the code, you would need to read up on “using blocks”, and StreamWriter too.
Wu wei
Trying to be all mysterious, I mentioned above that if you use a pre-processing tool in a memoQ online project, something interesting will happen even if the tool itself doesn’t do anything. (That is, if your pre-processing tool just writes out the same file that it gets as input.) So, what is it that you achieve by doing nothing? The answer is: you force the import to happen on the server side. When you import an actual file and your project is set up for pre-processing, then the memoQ client will simply upload the source file to the server, where memoQ TMS (memoQ server) will perform all the heavy work of parsing it and preparing a translation document out of it in the project. In normal projects, most of the heavy work is done by the memoQ client, and it just uploads the “finished product”. This might be an uninteresting technical detail for average files, but if you are importing a huge multilingual Excel file, which, last time I checked, could require hundreds of megabytes or even a few gigabytes of memory to import in memoQ, then it can make sense to pass the duty on to the server machine. I’ve helped teams use this trick when the PMs ran out of memory and importing some huge Excel files took them hours instead of minutes because of the crazy performance drop caused by the PC having to use the paging file (swap). An additional interesting detail is that even if you set up the memoQ template to pre-process certain file types only (like *.txt), still all files will be imported on the server side in a project created from that template. So you can just add any “fake” pre-processing, even for an imaginary file extension: this effectively gives you an option to force import to happen on the server side, which is an option otherwise missing in memoQ.